Carea launches launches first-of-its-kind maternal service to proactively connect users with expert support using tracking data
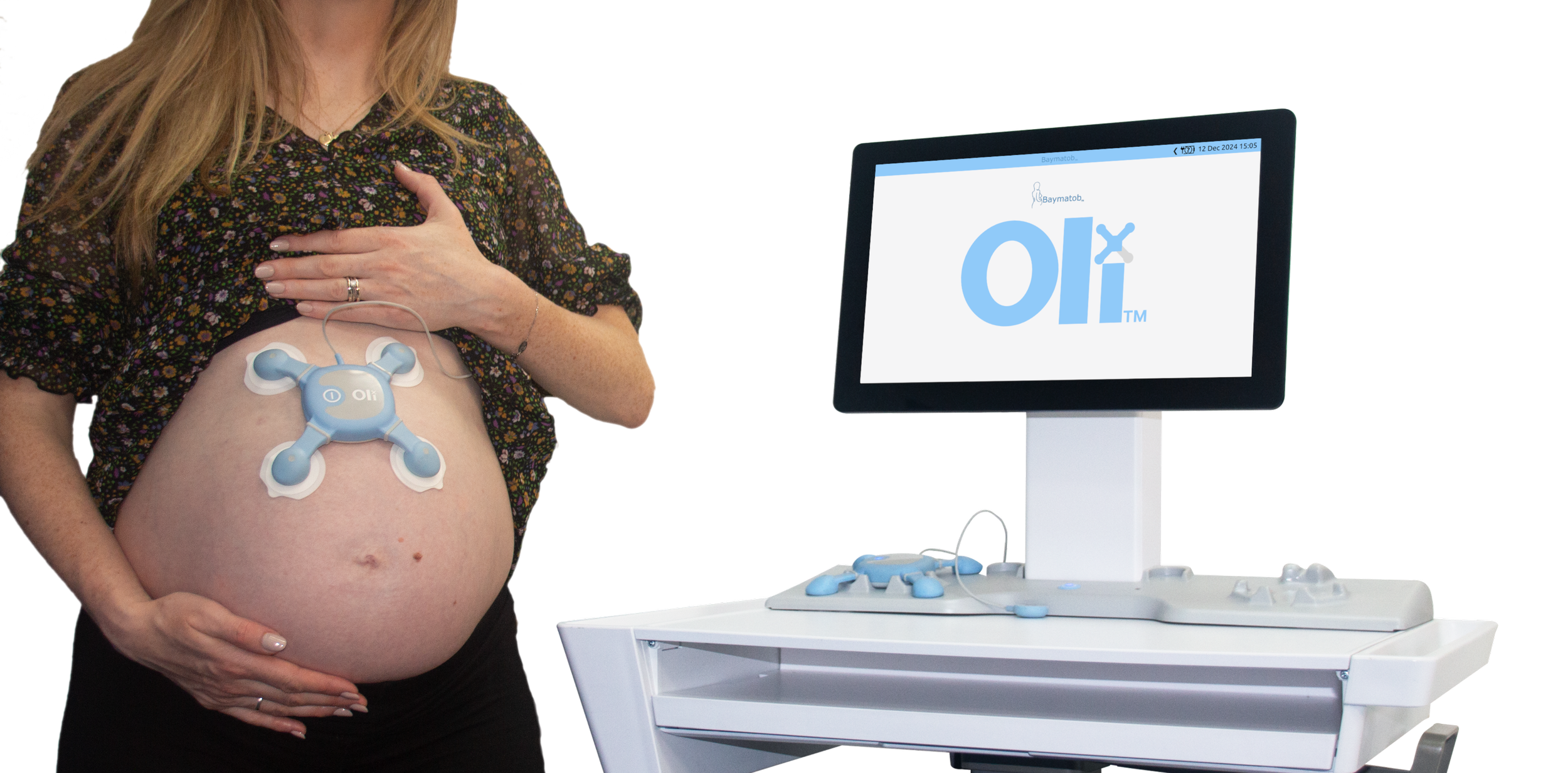
Predictive maternal and fetal monitoring device Oli completes recruitment of 1,000 mothers for pivotal clinical trial
1 in 4 women cannot identify their menstrual cycle length, despite widespread use of tracking technology
Innovation Landscape in Breast Health: What's Next for Patients, Research and Industry
The Silent Burden: Menopause and Our Economy
Juno Bio Opens First CLIA-Certified Sequencing Lab Dedicated Entirely to Women’s Health, Backed by Ada Ventures, Artesian, Illumina Accelerator, and Entrepreneur First
AI × Women’s Health Summit Unites 140 Clinicians, Investors and Regulators in London Call for Responsible Innovation
Emm Secures UK Regulatory Clearance for World’s First Smart Menstrual Cup
UK’s first breast density scanning clinic launches in Bristol to tackle hidden cancer risk indicator affecting millions
Women's HealthX Releases Full Agenda; Executives from the World Economic Forum, Takeda, and Gilead Confirmed to Speak in Boston, December 3–4
Natural Cycles Launches Sleep Insights Built for Women’s Cycles
The UK’s First Longevity Festival Comes to London
Joylux Releases Real-World Analysis of 23,000+ Women Finding Menopause Operates as an Interconnected Symptom Network
Sustaining Co-design in Women’s Health: Lessons Beyond the Pilot Stage
Femtech France Publishes the 2026 French Femtech Landscape Report
Oli secures $6.5M to advance predictive maternal and fetal monitoring ahead of market entry
Women's Health Innovation Summit Opens Submissions for 2026 Innovation Showcase
Lifesum and Calm Are Rethinking Digital Health as a Connected System
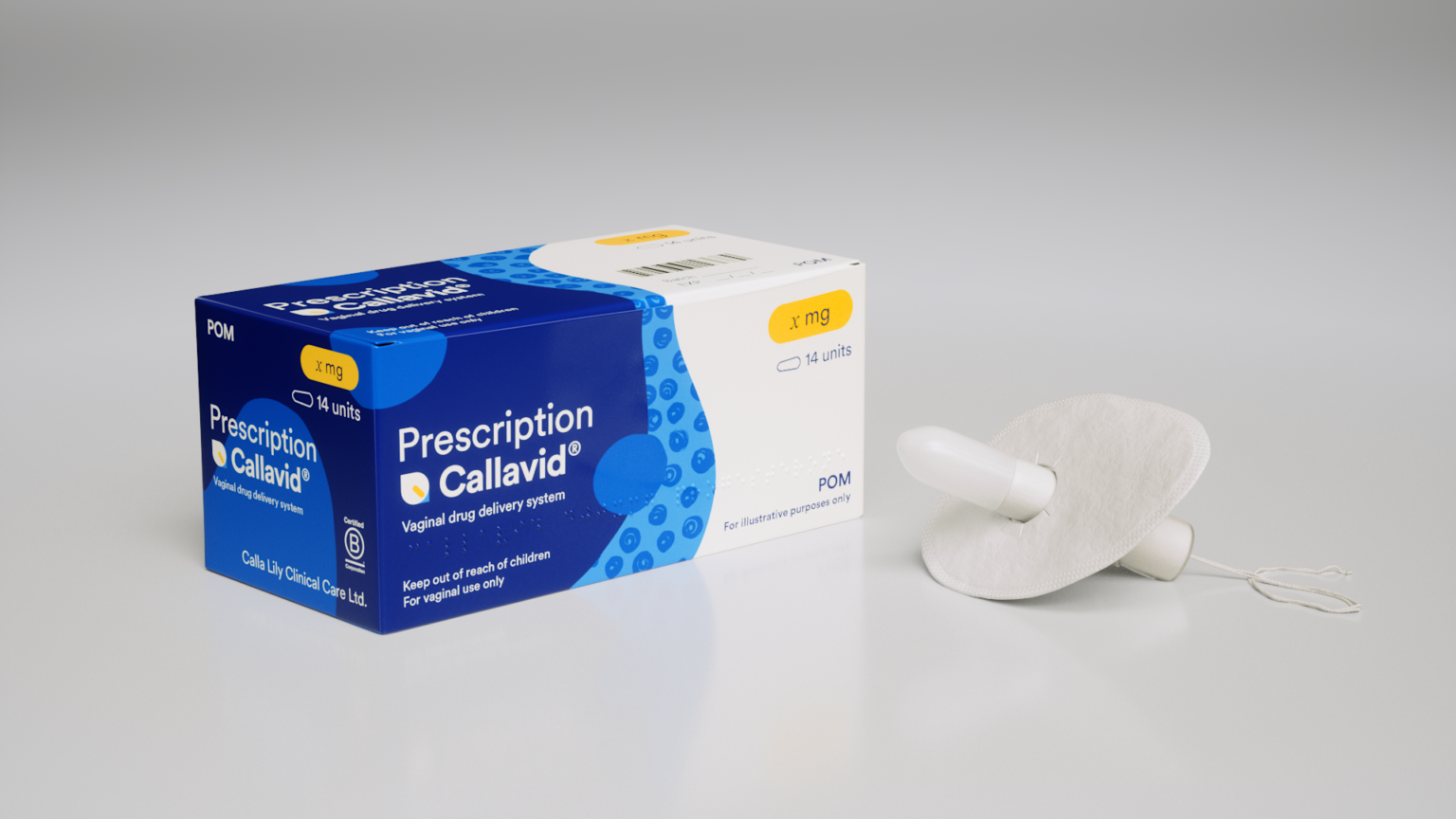
Calla Lily Clinical Care doses first patients in clinical trial for intravaginal drug delivery platform for threatened miscarriage
Women’s HealthX Unveils Northwell Health, Corewell Health, Biogen & more to headline the Chronic Disease Stage Spotlighting Sex-Specific Data Gaps in Research, Diagnosis, and Care